Local LLM Model Comparison
I’m working on a project I’m calling “Deck Chat”. It’s basically an online deck with some tracking and a chatbot. The chatbot will be powered by some flavor of LLM and the context/prompts will use the notes from the deck and any other information you want to include (e.g. a FAQ, whitepaper, documentation, etc.). I know all the hype about LLMs comes from ChatGPT, but I’m cheap, and using that would be too expensive. I got a 16G Radeon 4080 card last December and want to try to use it instead.
So, here is the experiment: I’m going to choose a couple of the larger, more often used models off of huggingface and compare their prompt outputs. I’ll use a shorter and a longer prompt. The shorter prompt will help me get a feeling for how well it generates interesting text. The longer one will let me know how well i might expect it to do when I start loading the prompt with more context (as needed in a conversation about the deck).
Let’s go!
HuggingFace
Hugging Face has the largest open source model repository. Most recent LLM researchers publish their models to the repo along with links to collateral such as papers and blog posts. If you are planning to self host, this is a great place to get your foundation model. If you don;t have enough power locally, they also provide hosted solutions and infrastructure.
Here are the models I’m going to use.
gpt2-xl.- size on GPU: 7502MiB
- This is one of the original models that sparked LLM excitement.
- 1.5B parameters
- data source: WebText. 40G. reddit and other sources.
EleutherAI/gpt-neo-2.7B.- size on GPU: 11840MiB
- Eluther.ai released this a couple of years ago.
- 2.7B parameters
- data source: The pile. 825G of collected datasets.
google/flan-t5-xl.EleutherAI/gpt-j-6B:float16.- size on GPU: 15500MiB
- Eluther.ai released this about a year ago. I am running it using float16 parameters because the full float32 is too big to fit on my card.
- 6B parameters
- data source: The pile
When using gpt2-xl and EleutherAI/gpt-neo-2.7B I’m going to use this config for inference:
response_max_tokens = 100
generated_text_json = generator(prompt,
do_sample=True,
max_new_tokens=response_max_tokens,
min_new_tokens=2,
clean_up_tokenization_spaces=True,
return_full_text=False,
stopping_criteria=stopping_criteria,
early_stopping=True)
For flan-t5-xl and gpt-j-6B I’m running with this config:
response_max_tokens = 100
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generated_ids = model.generate(
input_ids,
do_sample=True,
num_beams=2,
renormalize_logits=True,
temperature=0.9,
max_new_tokens=response_max_tokens
)
A note if you want to do this to, some models output the whole prompt + completion, others can return just the completion. If the model returns the prompt and completion (looking at you gpt-j-6B) you can trim it with this snippet:
generated_text = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:])[0]
Short Prompt
The short prompt goes like this:
prompt = f"""You are the CEO of a tech startup.
You are building a Web3 application that is going to change the way finance works forever.
You're in the process of raising money and being questioned by an investor.
Answer the following questions politely and professionally.
{ context }Question: {question}
Answer:"""
Then I ask 4 questions and add the question and answers to the context of the prompt.
- what does your app do?
- how much money will we make?
- how exactly does your app work?
- how much money have you raised?
I figure there’s probably some crypto news and articles in these web corpora. It might be amusing to see how each of the models pitches a web3 idea.
gpt2-xl
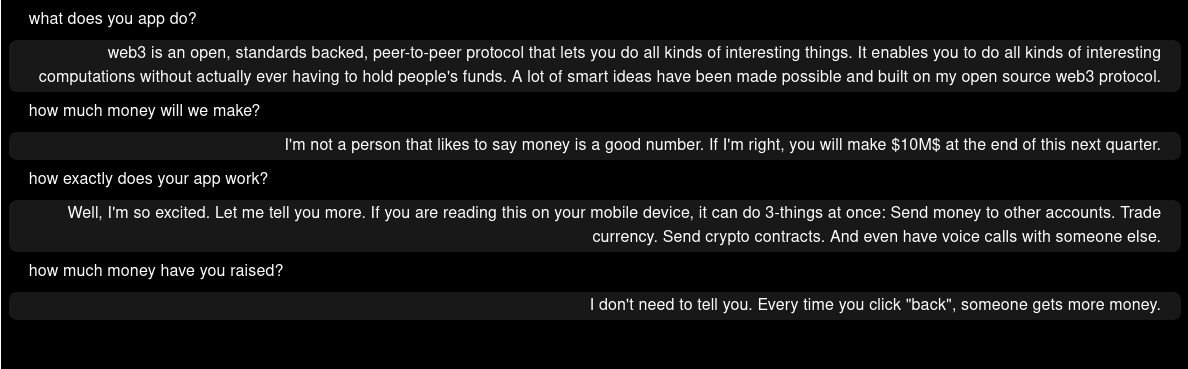
gpt-neo-2.7B
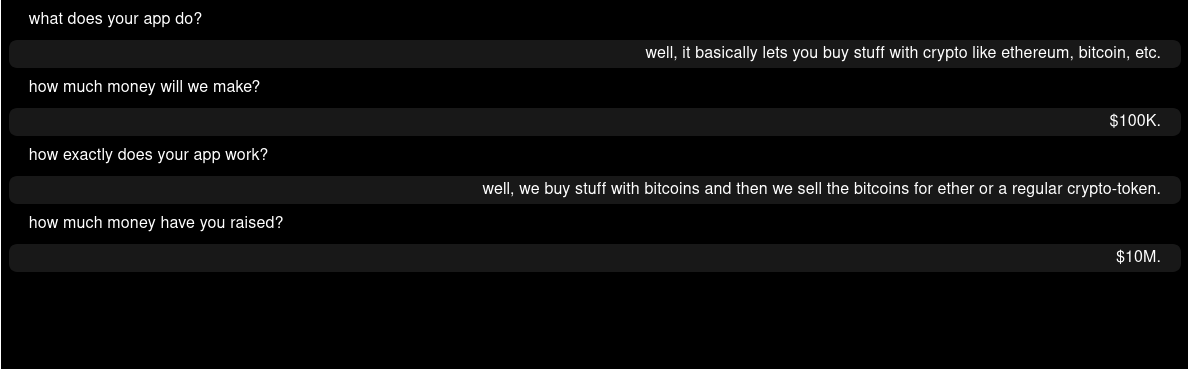
flan-t5-xl

gpt-J-6B

I ran each of them a couple of times and just picked a fairly typical output. Of these, I like the original GPT one the best from a narrative perspective. The rest are fairly succinct. This could be due to the settings at inference time, so I’m not making any conclusions here. But, if I was to move forward with a short prompt like that, the original gpt2-xl would be a pretty strong contender.
Long Prompt
I would expect to get better answers with a longer prompt. I’ll give it more to work with to set the tone of the conversation, and more info to draw on when answering the questions.
prompt = f"""You are the CEO of a tech startup.
You are building a Web3 application that is going to change the way finance works forever.
You're in the process of raising money and being questioned by an investor.
Answer the following questions politely and professionally.
Question: what is web 3?
Answer: Web3, also known as Web 3.0, is a term that refers to the next evolution of the internet,
where instead of relying on centralized servers and intermediaries, the internet is powered by decentralized technologies such as blockchain.
Question: why is it interesting or important?
Answer: In a web3 environment, users have greater control over their data and interactions with other users,
and transactions are secured and verifiable through distributed ledger technology.
This allows for the creation of decentralized applications (dApps) and new business models that were not possible with previous versions of the web.
Question: how are you going to change finance?
Answer: We're going to make it easier to borrow and loan money.
Everything will be instant and on-chain.
{ context }Question: {question}
Answer:"""
gpt2-xl

gpt-neo-2.7B

flan-t5-xl

This one puzzled me. I suspect what is happening here is that my question is very similar to one of the few-shot examples. So when it reuses the answer, and puts it back into the prompt, that the answer just becomes super important and nothing else comes back.
So, I tried asking in a different order and I got a different result.
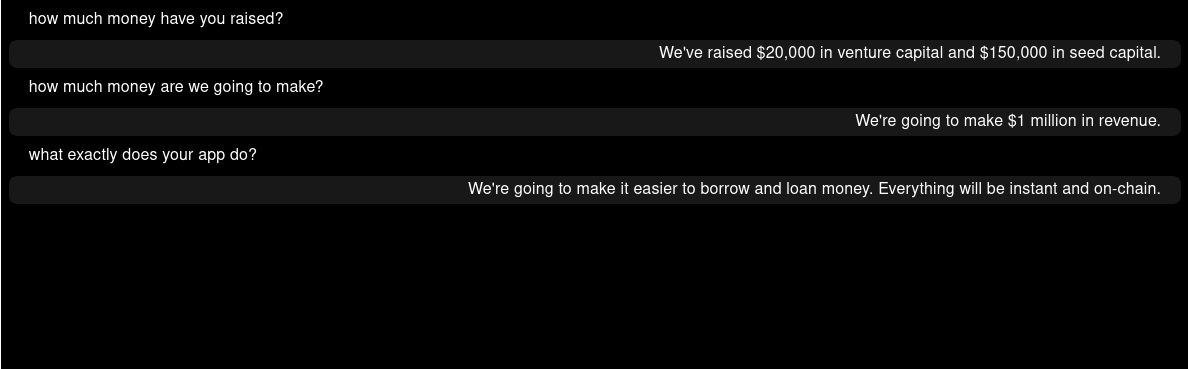
I think this might be an overfitting issue since the model was trained, and then fine tuned afterwards.
gpt-J-6B

The gpt-neo model had a stronger narrative after giving it a little more info. None of the stories were particularly compelling (I wouldn’t invest!) but I think gpt-J-6B might be the most accurate story for web3 companies trying to raise money at the seed stage.
Observations
Some of the things that I noticed (in no particular order):
- For completions, it pretty hard to judge quality. It’s very subjective which one you like better. Even if you have a model you think you like, by changing how it does inference, you can get qualitatively different outputs.
- These local models are nice for some use cases, but aren’t ready for a “Deck Chat”-like conversational AI. The main limitation is input token length. To provide the context to give good answers, you can’t just pull a model off of the shelf and feed it a few examples. It makes up all kinds of stuff.
- You can shard models and run in float16 (or even int8) if you want to run a big model on a smaller card. Using the accelerate framework to do it makes it possible (though I wouldn’t call it easy yet).
- Originally I built the backend on FastAPI, but refactored it to Flask. I don’t have enough GPU ram for multiple workers. To really serve multiple workers, I need to think a little more about how to structure the app and what frameworks is right ot run it.
- Bigger models don’t always mean better results. Performance will depend on the task at hand, whether you fine tune, how you write the prompt, and how you do inference.
Conclusions
So, I think the path forward for me is to use a hybrid approach where I:
Offline:
- Collect documents + Q&A examples within a domain.
- Build a GPTIndex on top of those documents
- Design prompts to:
- summarize text to use as context
- use context and user question to get answers
Online:
- In something like LangChain, use user question to query for context.
- Use context and user question to get a response.
At that point I can reassess whether a smaller model will be sufficient, or I need to use one of the commercial options. It might be worthwhile to look into the commercial options before building this workflow out to see if anything there changes my mind.
These smaller models are interesting in their own right. I think they will be useful for single task problems like sentiment analysis, search/embeddings, and multi-class classification. When combined with a larger LLM, we can optimize the cost/benefit tradeoff. Not everything will need the newest state-of-the-art LLM.