LLM-powered Fact Checker walkthrough
Sign up for notifications and articles!
I recently built a large language model (LLM) application that I like to call “The Big Lebowski Fact Checker.” A fact-checker is usually a person or service that checks whether a statement is true. During election cycles we see a lot of fact checkers working to sift through all of the statements politicians make to tell whether they are being honest or misleading. Fact checking is useful in other contexts as well when a person or business makes an claim.
Although the code isn’t public yet, I’ll include snippets here to help you understand how it works. Keep in mind that using LLMs isn’t fast, and scaling is slow on Google App Engine, so please be patient if you go to check it out.
Motivation
My motivation for building this app goes beyond the cool domain name and is threefold. First, there’s a lot of press about how bad LLM hallucination is, with LLMs often portrayed as very confident 8-year-olds mansplaining to anyone who dares listen. While I’ve seen this firsthand, it can be prevented. Including “facts” in the prompt and instructing the LLM to only use the data in the prompt to answer questions does a decent job of eliminating make-believe. Of course, it can still be wrong sometimes, but that’s usually due to the prompt and data input.
Secondly, this app includes core components that are important for building LLM apps. If you wanted to get started as fast as possible then Python libraries like LangChain and LlamaIndex provide off the shelf implementations for web search, text extraction, and summarization. Since I learn best by doing, I wanted to write my own versions of those components as well as a simple in-memory vector database.
Lastly, I considered where LLMs are headed. Around five years ago, large newsrooms employed sports journalists to write previews for sporting events. Now, a small handful of companies use statistics to produce previews for major news outlets. Fact-checking is currently a manual process performed in newsrooms by researchers who are thorough and follow a process. I can envision a future where they have a better suite of tools that allows them to be editors and proofreaders rather than search, summarize, and compare grunts. Maybe someone will discover this application and find it useful .
I love creating software with character, as I believe it adds an extra dimension to the application. In this case, I chose “The Big Lebowski”. A scene in the movie features The Dude saying, “Yeah? Well, you know, that’s just like, uh, your opinion, man.” This inspired me to search for the domain yeahwellthatsjustlikeyouropinionman.com, which, unsurprisingly, was available!
User Experience
The ideal user for this application is a fact-checker, someone who needs to corroborate or debunk a statement. When a user first visits the site, they are greeted with a retro theme and a text box to enter the statement they want to verify.
 Landing page where user has already entered a statement.
Landing page where user has already entered a statement.
After submitting the statement, the backend begins the process. To keep users entertained while they wait for a response, a playlist of Big Lebowski clips is provided (enjoy!).
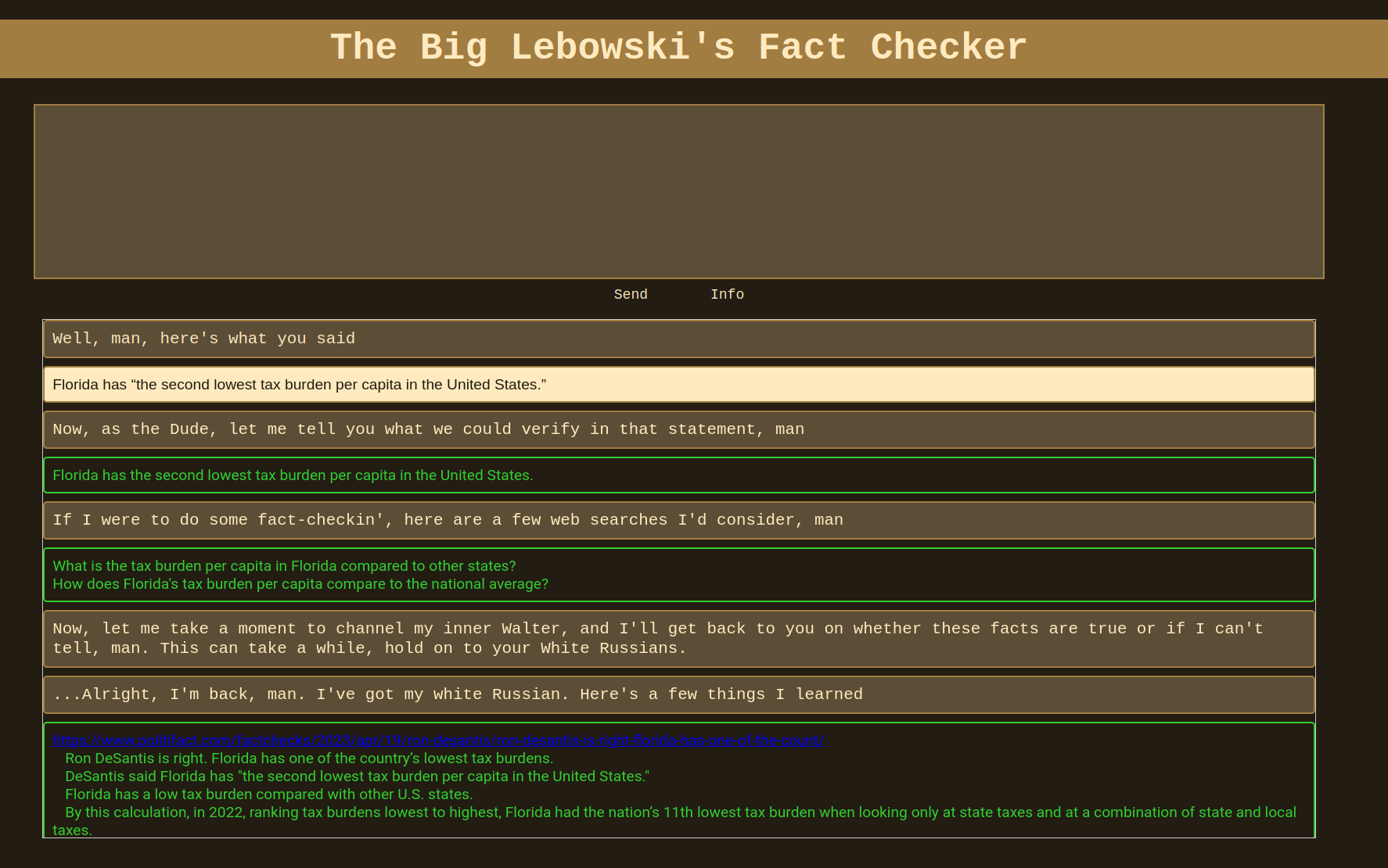 After submitting the fact you get a list of searches and sources.
After submitting the fact you get a list of searches and sources.
Upon completion, users receive a list of google searches that will be performed along with the results: links to source documents and key text elements relevant to the statement. These text elements are used to help determine if the statement is true, false, partially true, or unknown. That verdict is provided along with supporting evidence in the final message before resetting the input text box.
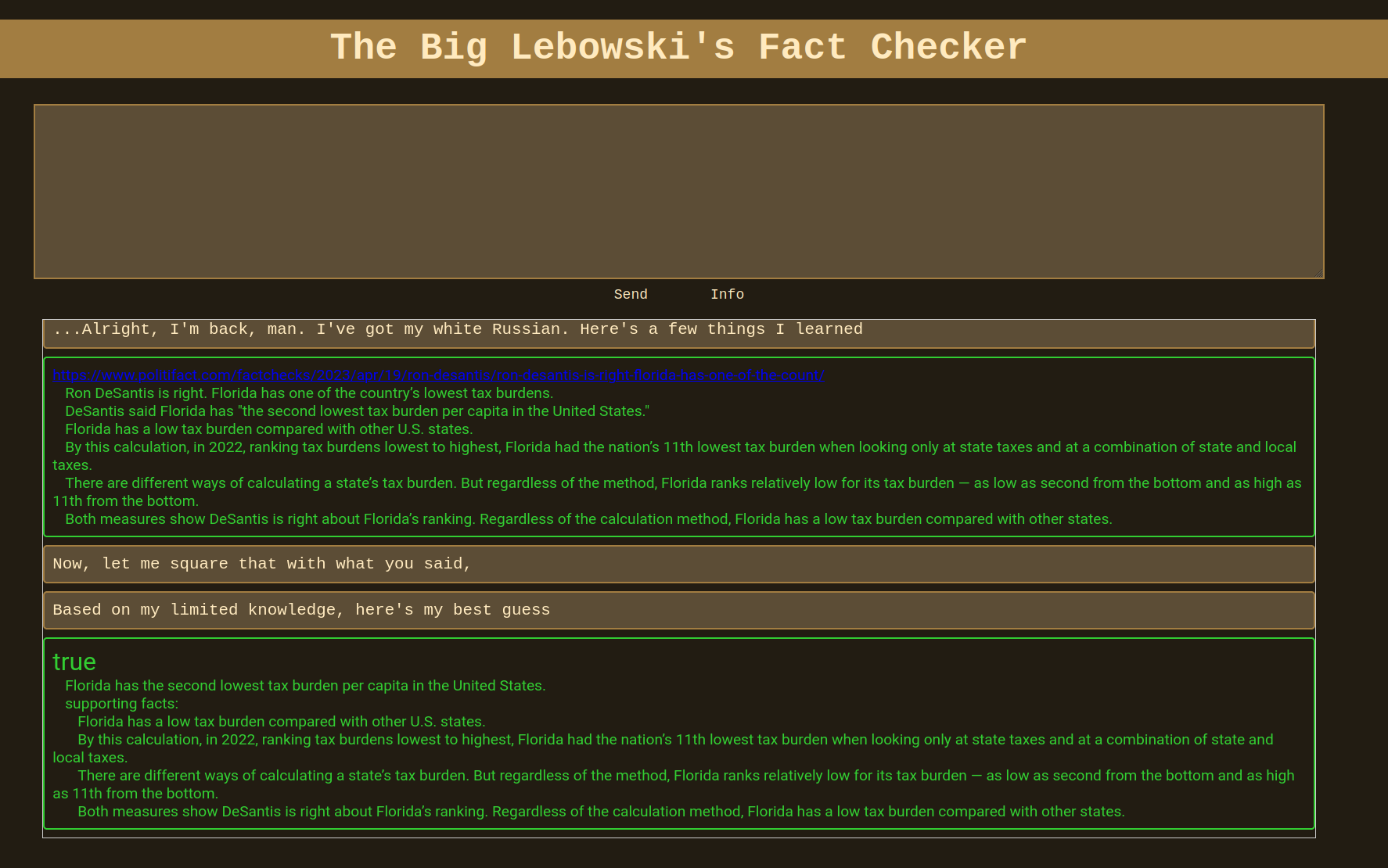 The sources are used to determine whether the statement is true, false, partially true, or unknown.
The sources are used to determine whether the statement is true, false, partially true, or unknown.
Application Overview
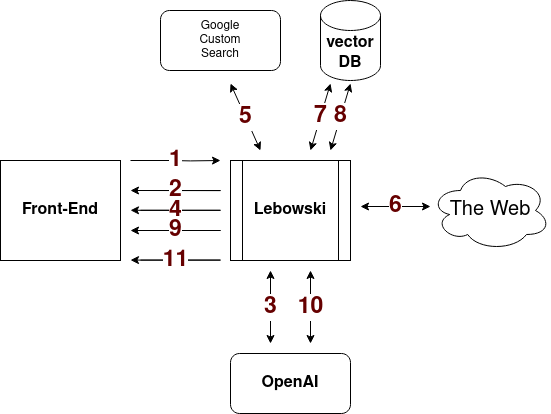
We’re solving this problem using a Retrieval Augmented Generation (RAG) process with LLMs and custom prompts. The diagram above demonstrates the flow of information through the application, and detailed steps are listed below.
-
When a user first visits the page a websocket is opened to stream data back and forth. The first data sent over the websocket is when the user submits their statement for fact checking.
-
Lebowski repeats the statement to ensure it remains visible, as the text block toggles into the YouTube player for in-flight entertainment. Because latency can be so bad, I try to minimize it by streaming results from the backend as soon as they’re ready.
-
The first prompt includes the user’s statement and some instructions. The LLM tries to figure out if the statement just has a bunch of opinions in it, or if there is something that could be fact-checked. For instance, if you say something like “Hamburgers are the best!”, Lebowski will reply “That’s just like, your opinion man.” I like hamburgers too, but that’s really just an opinion and not something we could fact check. The other thing the LLM returns are some google searches we can use to find articles and webpages to help figure out whether the statement is true.
-
Lebowski sends a message to the frontend with the statements it will try to verify and the web searches.
-
The web searches are performed, collecting the top 3 hits from a list of several “trustworthy” sites for each search phrase.
-
For each search result, we grab the HTML from the URL and parse out the article text. This part can be kind of tricky. There is a lot of extra content on the pages that aren’t at all relevant to the research we’re trying to perform.
-
After cleaning the text, we compute embeddings for each paragraph of text from the webpage (new line separated) and insert them into a vector database. In this case, we’re not saving the data between searches, so we’re using an in-memory database that we’ll delete later.
-
Once all the paragraphs are inserted into the vector database, we embed the searches and statements and retrieve the top 4 matches for each. These are then deduplicated and saved for use in the rest of our prompts.
-
Lebowski sends the documents and links to the websites from the web search to the UI for your perusal, man. At this point, you should be able to read through the results for each page and get a feeling for whether your statement is true or not. If you’re interested in how well the vector database information retrieval works (and how well the parser works), you can click on the links, go through the web pages, and see if the selections are indeed the most relevant.
-
Finally, we use the statements to be verified and the information from the documents in a prompt to determine their truthfulness and the most relevant statements for proving so.
-
The final message is sent to the frontend, and the text box is reset.
Information Extraction: Two Implementations
One of the steps in this process is extracting all relevant information from a web page related to the user’s statement. A randomly chosen webpage often contains ads, banners, links, and other irrelevant content. For example, take a look at this Politifact page, which includes a header and article along with other items such as donation solicitations, sources, links to other fact checks, and site navigation.
As humans, we can quickly skim through the unimportant content and find the relevant information, but a web scraper can’t do that. Creating custom scrapers for every domain is a possibility, but it requires constant updates and building new ones when adding new sources.
Here, I’ll explore two different approaches to extracting the data: using an LLM to summarize and extract relevant facts, or computing embeddings to find the most relevant phrases. I first tried the all-LLM route.
LLM only: Summarization Challenge
The pure-LLM route involves getting the webpage HTML, parsing out the visible text, and passing the entire thing to the LLM in a prompt, asking it to extract the relevant parts.
For reference, this is how we get the visible text using BeautifulSoup:
def get_text_from_url(url: str) -> str:
s = requests.Session()
s.headers.update(headers)
response = s.get(url)
soup = BeautifulSoup(response.content, "html.parser")
for script in soup(["script", "style", "head", "title", "meta"]):
script.extract()
visible_text_elements = soup.find_all(text=True)
visible_texts = []
for element in visible_text_elements:
e_str = (
element.replace("\r", " ")
.replace("\n", " ")
.replace("\t", " ")
.replace("\\r", " ")
.replace("\\n", " ")
.replace("\\t", " ")
.strip(" \n\t")
)
if len(e_str) > 20:
visible_texts.append(e_str)
return visible_texts
This works reasonably well. The resulting array of text will contain some longer extraneous material but generally gets rid of a lot of noise. Further refinements will be discussed in the next section.
Once we have the text we want to parse, we pass it to the method that extracts “facts” from the document. We’re using GPT-3.5-turbo and splitting the messages into different roles.
Here’s an example prompt system message:
GET_DOCUMENT_FACTS_SYSTEM = """You are a summarization and fact checking API written in typescript. Find supporting evidence that either proves or disprove the following statements. If the relevant evidence is in a table or chart include the data point but not the entire chart of table. Return valid JSON with a single 'documentFacts' key whose value is an array of strings. If the user statement is not supported or disproven by the document reply "NONE"."""
Here’s the corresponding prompt
GET_DOCUMENT_FACTS_PROMPT = """EXAMPLE
'''statements
dogs are animals
cats are dogs
fish and trees are animals
'''
'''document
encyclopedia definition of animals and the kingdoms
'''
ANSWER=documentFacts
EXAMPLE
'''statements
dogs are animals
cats are dogs
fish and trees are animals
'''
'''document
document about fried fish
'''
ANSWER=NONE
'''statements
{USER_FACTS}
'''
'''document
{DOCUMENT_TEXT}
'''
ANSWER="""
The problem here is that the page contents are too large to fit in the prompt without overflowing the context of the LLM (I do not have access to the 32K version of GPT-4). Langchain and other libraries provide a default implementation for this that do chunking with overlaps. I chose a slightly different strategy where I split the text into paragraph chunks and poerformed an iterative summarization on those chunks and then combined and deduplicated them in the end.
The number of chunks needed can be figured out using tiktoken (tiktoken is the library OpenAI uses to compute the base pair embeddings (BPE) for sentences by converting words into indices) and some algebra:
system_message = {"role": "system", "content": GET_DOCUMENT_FACTS_SYSTEM}
nl = "\n"
full_text_doc_facts_prompt = GET_DOCUMENT_FACTS_PROMPT.format(
USER_FACTS=nl.join(user_facts), DOCUMENT_TEXT="\n".join(document_text)
)
user_message = {"role": "user", "content": full_text_doc_facts_prompt}
n_system_tokens = num_tokens_from_messages([system_message])
n_document_tokens = num_tokens_from_messages([system_message, user_message])
# we only want to pack the messages 3/4 full so that there is room for the reply tokens
per_msg_token_limit = 0.75 * MODEL_MAX_TOKENS
n_chunks = int(n_document_tokens / per_msg_token_limit) + 1
The more accurate version computes the fixed parts of the prompt, so you know how many actual tokens you can add to each chunk.
no_text_doc_facts_prompt = GET_DOCUMENT_FACTS_PROMPT.format(
USER_FACTS=nl.join(user_facts), DOCUMENT_TEXT=""
)
user_message = {"role": "user", "content": no_text_doc_facts_prompt}
base_document_tokens = num_tokens_from_messages([system_message, user_message])
allowed_tokens_per_partial_doc = per_msg_token_limit - base_document_tokens
doc_chunks = chunk_doc_list(document_text, allowed_tokens_per_partial_doc)
Doing it like that, you get an array of document chunks, and iterate over that to send them. In this prompt, I want to newline separate each of the paragraphs, so I include that in my chunker. Note that I could be overestimating the number of tokens in a given chunk if the ‘\n’ is a part of a BPE after adding to the previous paragraph. This is close enough for me right now.
nl_tokens = num_tokens_from_string("\n")
def chunk_doc_list(docs: list[str], max_tokens_per_chunk:int) -> list[str]:
chunks = []
chunk_str = ""
chunk_tokens = 0
for doc_part in docs:
this_chunk_len = num_tokens_from_string(doc_part)
if this_chunk_len + chunk_tokens <= max_tokens_per_chunk:
chunk_str += "\n" + doc_part
chunk_tokens += nl_tokens + this_chunk_len
else:
chunks.append(chunk_str)
chunk_str = doc_part
chunk_tokens = this_chunk_len
chunks.append(chunk_str)
for chunk in chunks:
assert num_tokens_from_string(chunk) <= max_tokens_per_chunk
return chunks
Doing it this way, we split the doc into several chunks, summarize and extract the relevant info from each one and then re-combine them together. The recombined version can have the same problem as these individual ones, so I deduplicate and summarize those as well.
The system message and prompt go like this:
DEDUPLICATE_FACTS_SYSTEM = """You are a deduplication API. Take the following list of facts are return a deduplicated and condensed list of facts. The resulting list should be shorter than the original list. Summarize the facts as much as possible. You must reply with valid JSON."""
DEDUPLICATE_FACTS_PROMPT = """EXAMPLE
'''facts
cats have 4 legs
dogs usually have four legs
cats and dogs are both animals with 4 legs
'''
RETURN=facts
EXAMPLE
'''facts
spiders are hairy
dogs usually have four legs
cats and dogs are both animals with 4 legs
'''
RETURN=facts
'''facts
{DOCUMENT_FACTS}
'''
RETURN="""
Similar to the last one, you have to split it up and do it iteratively to get a small number of facts that can fit into the next set of prompts. This can turn into many LLM calls and a lot of added latency even if you parallelize them.
LLM + Vector Database: Parsing Challenge
When using a vector database to find the relevant phrases, the HTML parsing and content extraction parts become much more important. The sentence_transformers models from huggingface (and sentence embeddings in general) are much more sensitive truncated sentences than than the GPT LLM series. These sentence embedding models are trained to take a sentance and translate it into a sparse vector space based on meaning. If a sentence is truncated or malformed, it might lack meaning and the embedding model will struggle to map it to a vector in a meaningful way. Meanwhile, a LLM doing summarization can just kind of ignore or guess at bad text and include the parts it does understand. By the way, if you’re not familiar with what a vector database is, no sweat, you can find a pretty good explanation here.
Many webpages are off limits to web crawlers and robots. My approach to finding good reference material is probably a grey area, and so I’m not going to go into detail here. If you’re really interested, try reaching out to me via LinkedIn or email. It involves generating cookies on my machine and then trying to use those when scraping.
The best library I’ve found for pulling text out of a website is trafilatura
def get_text_from_html(contents_html: str) -> str:
return trafilatura.extract(contents_html)
It’s the only one I’ve seen with a really nice writeup on its evaluation metrics
Here’s how I filter out the top paragraphs.
v = VectorDatabase()
def filter_texts(queries: list[str], full_texts: tuple[str, str]) -> dict[str,list[str]]:
map_texts = {}
for (link, full_text) in full_texts:
texts = full_text.split('\n')
map_texts[link] = texts
v.add(texts)
filtered_paragraphs = list()
for query in queries:
filtered_paragraphs += v.get(query, n=4)
filtered_map = {}
saved_paragraphs = set()
for word in filtered_paragraphs:
for key, val in map_texts.items():
if word in val and word not in saved_paragraphs:
saved_paragraphs.add(word)
if key not in filtered_map:
filtered_map[key] = list()
filtered_map[key].append(word)
logging.debug(f"len filtered_paragraphs: {len(filtered_map)}")
# clear all of these from the vector db.
v.clear()
return filtered_map
A few notes:
-
I am choosing the top 4 documents for each query across all of the webpages I’ve scraped. I find that some of the web search results are not really relevant.
-
The queries are both the statements I’m trying to verify as well as the search terms I passed to Google. I find that using both gives me more information to work with.
-
If I were to revisit this, I would probably keep the scores and try to do something clever with them to further reduce the number of paragraphs returned from the method.
Comparison of Methods
In general, the LLM seemed better at identifying the right parts of information and extracting them. However, the cost was too high, both in terms of latency and price. Because it took so long to parse a single long page, I retrieved fewer results. This hurt my accuracy.
The vector database approach worked pretty well and shaved a significant amount of latency off the total execution time. One must be careful about the choice of embedding model (I tried a few from the HuggingFace repo using sentence_embeddings and found ‘’), but once that is sorted, it does well enough. As you can see from the two sections above, the vector database approach is much simpler.
It’s possible that the improved text extraction from the second approach would reduce the number of LLM calls in the first section. I didn’t take the time to carefully check that.
LLM-based extraction is abstractive and not extractive. If it were extractive, then all of the lines in summary would also be lines from the original source. However, with abstractive summarization, I can’t point to a specific line in the original text where the information came from. LLM + vector database is extractive, so if I wanted to, I could construct a deep link back to the article and highlight the line it came from. Both have their advantages and disadvantages, but for a fact-checking application, direct references to the source material are preferred.
GPT-3.5-turbo vs GPT-4
I developed both versions of the app using GPT-3.5-turbo. I received API access to GPT-4 and tried it as a drop-in replacement but found it slow. GPT-4 seemed to be as accurate as GPT-3.5 without additional prompt tuning. However, the latency was much higher, making the performance improvements of GPT-3.5 more attractive.
Conclusions
Please keep in mind that the app is not production grade. It is under-provisioned due to cost considerations, which affects its performance. Nevertheless, the app can still function as a reasonably effective fact-checking tool, offering more accuracy than a random guess.
Releasing the complete code is not planned at the moment, as it is quite disorganized. However, the provided code snippets and outline should offer a general understanding of the app’s structure and functionality. I welcome you to connect on LinkedIn to discuss further, share experiences, or report any issues with the code. Hopefully, readers will find something valuable and engaging in this project!