LLM Application Primer
LLM Applications
Unlike traditional web development, which focuses on building web pages and applications, Large Language Model (LLM) application development involves working with natural language prompts and integrating your data sources to create workflows. The LLM provides a natural language interface for your users to provide input and to generate natural language output. However, the LLM is limited. The content that is in it’s training set is all it knows. It’s the same for all users and isn’t very good outside those bounds.
If you want to build a differentiated LLM AI product you have to either a) use the model in a novel way (which can then be ripped off) b) bring a new dataset to it and do something more focused/domain specific than the general purpose LLM or c) build integrations on top of it that do useful stuff.
LLM Application Development Process
There are two phases and 8 steps to LLM application development.
-
Define the problem: The first step in building an LLM application is to define the problem that the application will be solving. This includes identifying the specific task that the model will be trained on and the type of data that will be used to train it. This is easily the most important step. The more specific and focused you can make the problem statement, the better your chances for success are.
-
Solution planning: Break the steps down from input to output so that they are as simple as possible. To make a metaphor, you want each step to be like addition, not like multiplication. You should have very simple steps that are easy for a LLM to reason about so that you maximize the probability that it gets things right. Read though techniques to improve reliability to get some ideas of how you can structure prompts. For steps where you need to add new information, make sure it fits into the context for the model you’re using. Have a plan to store input, intermediate outputs, and outputs so you can review them.
-
Choose an appropriate pre-trained model architecture: The choice of model architecture will depend on the task at hand. By browsing the hugging face model repository you can find many pre-trained models that are advertised at being good at a variety of tasks. There are also several paid model providers (listed later) you can integrate with for hosted LLM serving. You may need different models for different steps and you might need to do some fine tuning.
-
Integrate the model: Now that you have a plan and a model (or models) selected you need to build the application and integrate it into your workflow. This will likely involve using custom code and possible a LLM framework, some of which we outline below. Although the app flow for a LLM app is different from web development, the coding process is the same. Writing code, tests, and CI-CD pipelines are the usual tasks.
-
Test and evaluate: The final step is to test the application and evaluate its performance. This can include testing it on a hold-out dataset or by conducting user testing to see how well it performs in a real-world scenario. Evaluating the quality of the output of LLMs is an ongoing field of research. For more complex multi-step LLM apps, you can test intermediate steps as well as the end-to-end output. In general I rely on end-to-end test more at first because you get more “bang for your buck”.
-
Deploy: Once the application has been tested and evaluated, it can be deployed to a production environment, where it will be used by end-users. Similar to web development, there are numerous deployment options.
Once your application is deployed you move on to the next stage: Iteration. Unlike web apps, LLM apps generate data that can be directly incorporated back into the app to improve performance. LLM models can produce non-deterministic output (generative use cases), it’s important to monitor performance to know how your model is doing with real world data. Whatever data was used to train the model might not match the data it sees in production, there’s always a chance it performs poorly. Observability and monitoring are important investments.
-
Collect and process data: Because most LLM applications are built on top of pre-trained models, this data your app generates will be important for fine-tuning the model to improve performance and reduce your costs. It’s best practice to log all user interactions and have a process to review them to ensure good performance.
-
Fine-tune the model: You can fine-tuned to improve its performance on the specific task at hand. This can involve adjusting the model’s hyperparameters, such as its learning rate, and training it on your additional data. Using the data that your users generate while using the app is ideal for review and inclusion in a training dataset.
LLM functionality
For these LLM apps, the input and output are typically in the form of text. LLMs are accessed using prompts with instruct the LLM what kind of output to produce.
Canonical LLM outputs include:
- Text generation: LLMs are able to generate text on a wide variety of topics and in different styles, such as writing news articles, stories, and even poetry.
- Language translation: LLMs can be trained to translate text from one language to another, making it easier for people to communicate across different cultures and languages.
- Summarization: LLMs can also be used to summarize long documents or articles, condensing the information into a more manageable format.
- Question answering: LLMs can be trained to answer questions posed in natural language, making it possible for people to interact with these models in a conversational manner.
- Sentiment analysis: LLMs can be trained to determine the sentiment or tone of a piece of text, making it useful for tasks such as monitoring social media for brand sentiment.
- Reasoning: New approaches have been developed ot help LLMs reason about the world and reach conclusions that are usually true.
LLM inputs considerations:
- The prompt and context provided can’t be too long. Different models have different limits, but it’s often necessary to summarize long pieces of content when building a prompt.
- Similar prompts can result in wildly different outputs. Because LLM outputs are statistical in nature (some probability distribution defines what the output is), and the prompt is used to make the prediction, you often need to test different version of the prompt to get the one that answers your question the best.
LLM Application Frameworks
LLM application development is still in the very early stages. There are a few open source and a few paid/hosted application frameworks for building and deploying these apps. No clear market winner has emerged, but some of the open source tooling appears to be gaining traction.
Current Open Source Frameworks:
- Dust
- LangChain
- GPT Index
Hosted/Paid options
- Patterns.app
- HumanLoop
- Yurts.ai
Dust
Tagline: “Built on years of experience working with large language models. With one goal, help accelerate their deployment.”
Configure
Currently (2023-01-23) dust supports OpenAI, Cohere, and AI21 Studio models.
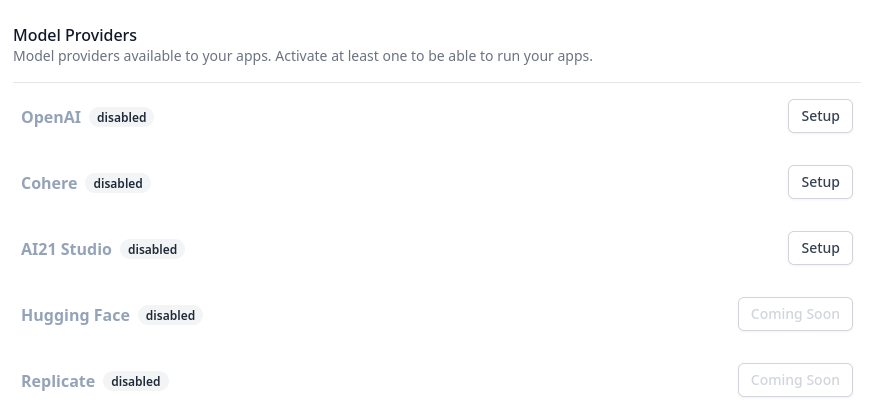
Currently (2023-01-23) dust only supports a few external data integrations, but has a few planned.
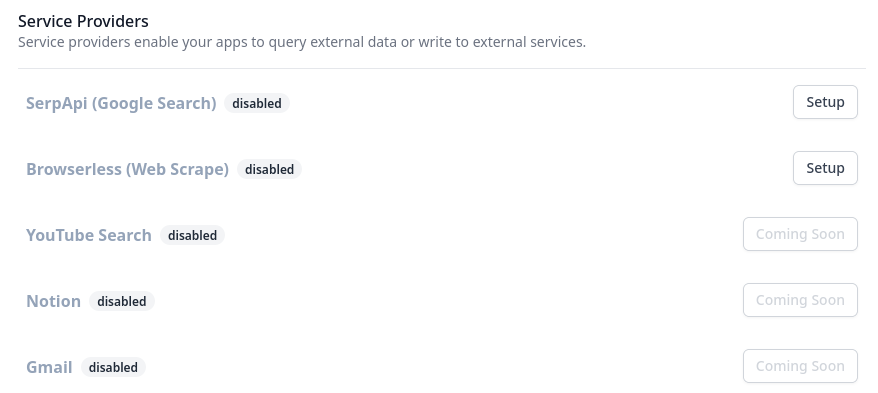
Build
Dust is a framework that provides a notebook style interface to explore a specification for your LLM chain. It reads kind of like a jupyter notebook maths example. You can build apps and deploy them to dust.tt and evaluate it via API or in the web app UI. You can generate the app specification (or clone an existing one) using the GUI builder.
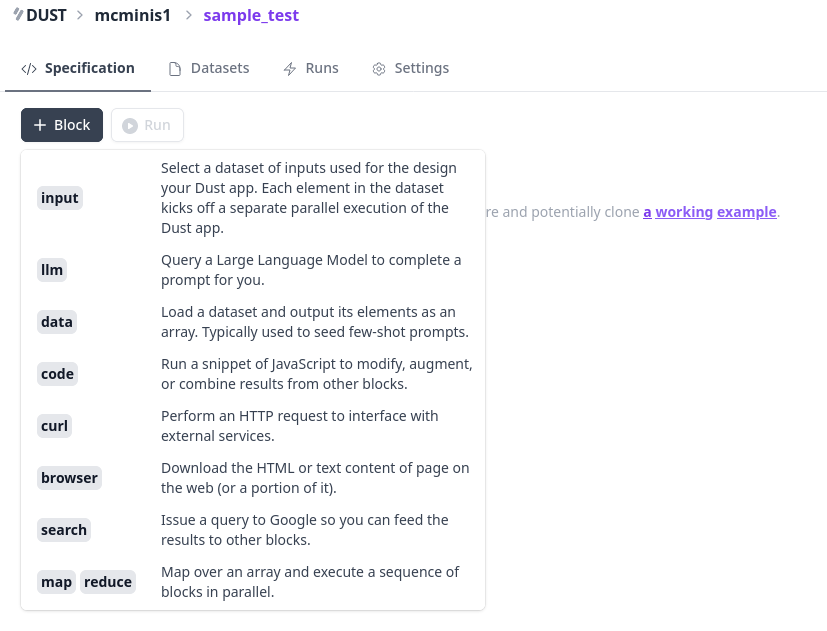
You can add new sample, training, or testing data manually:
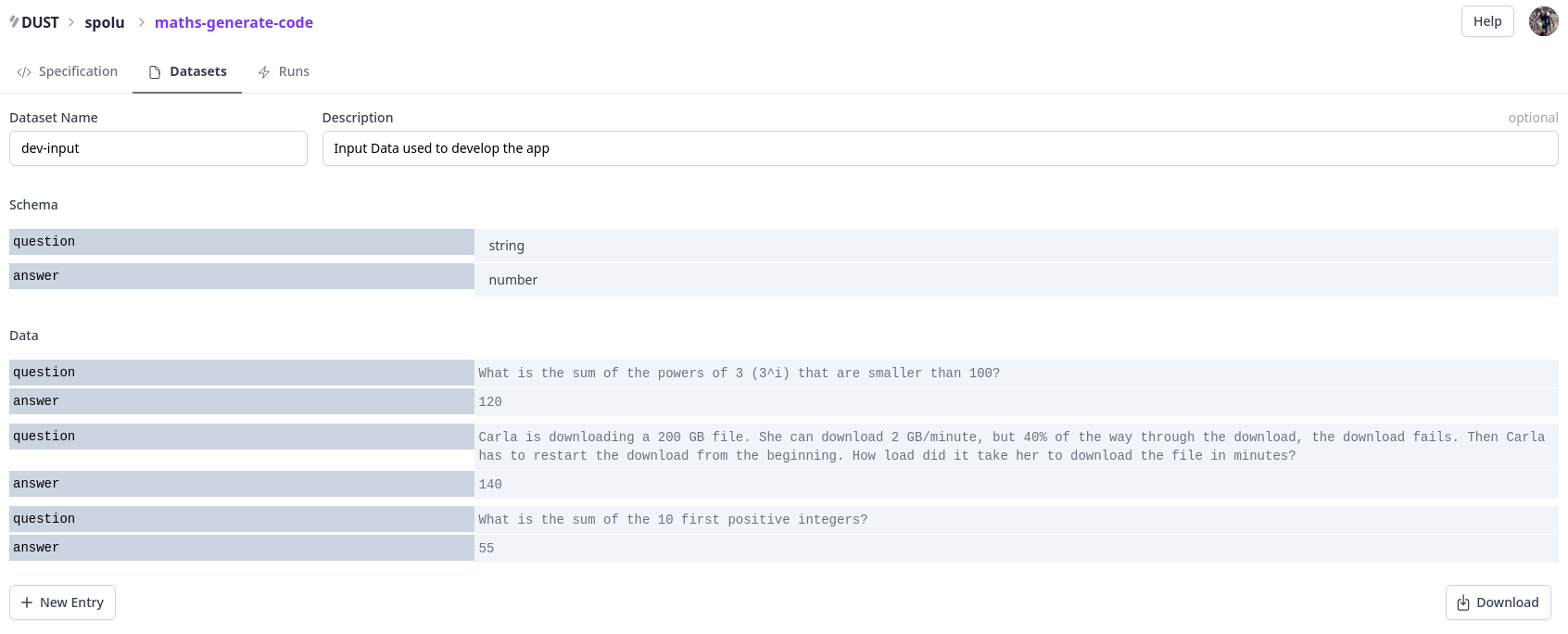
You can easily review past local or API runs:
Building and deployment seem pretty easy. Iterating seems a bit more manual. If you’re looking for something hosted and fairly easy to get started with, this is a good option. It doesn’t feel quite ready for production use.
Lang-Chain
Tagline: “Building applications with LLMs through composability”
LangChain is a python framework for building LLM applications. It makes it easy to manage LLM providers and chain together the steps in your app. It’s not a complete solution to building and deploying. Those parts would be handled the same as a web app (up to the developer to design and deploy).
Configure
LLM providers supported: OpenAI, Hugging Face hub, and the manifest wrapper. Using the manifest wrapper you can run a model locally and integrate with the app.

Build
Because LangChain is built on python, it’s easy to integrate with other data providers using the same libraries you would in a python application. It does also have some more LLM specific utilities built in to make LLM development easier:

It uses the cohere embeddings, and elasticsearch as the VectorStore.
One of the most useful parts of LangChain is the memory component. Memory is used to keep track of state between steps. There are several forms of memory you cna use depending on your use case.

For instance, if you wanted to create a ChatGPT clone you can use ConversationalBufferWindowMemory.
A few deployment options are outlined using other libraries.
If you’re a developer and looking for a library to help you build something, this is the go-to LLM application framework. You can integrate it into whatever else you’re building pretty easily.
GPT-Index
Tagline: “An index created by GPT to organize external information and answer queries!”
Configure & Build
GPT Index isn’t a general purpose LLM framework, it’s built to solve a particular set of problems:
- Provides simple data structures to resolve prompt size limitations.
- Offers data connectors to your external data sources.
- Offers you a comprehensive toolset trading off cost and performance.
The Index:
- Uses a pre-trained LLM primarily for reasoning/summarization instead of prior knowledge.
- Takes as input a large corpus of text data and build a structured index over it (using an LLM or heuristics).
- Allow users to query the index by passing in an LLM prompt, and obtaining a response.
It can be integrated with LangChain to provide an arbitrarily large memory. It also can use any of the LLMs LangChain can be configured to use.
GPT Index is a useful component for build LLM applications, but isn’t a full framework itself. Methods for
Patterns
patterns.app website.
Tagline: “Run and deploy web apps, task queues, massively parallel compute jobs, machine learning models, GPUs, and much more with a single unified framework for code and infrastructure.”
Patterns is a startup that started building a data engineering platform to enable mixed python/sql data workflows with rich integrations and an easy to use GUI editor. Since then, they’ve been adding a lot of functionality to enable more complex data flows including LLM apps. They recently published a blog post that demonstrates an offline fine tuning and slackbot serving workflow.
Configure
There is an out of the box OpenAI connector as well as one for Cohere.

Build
You can clone an existing app, or start from scratch.
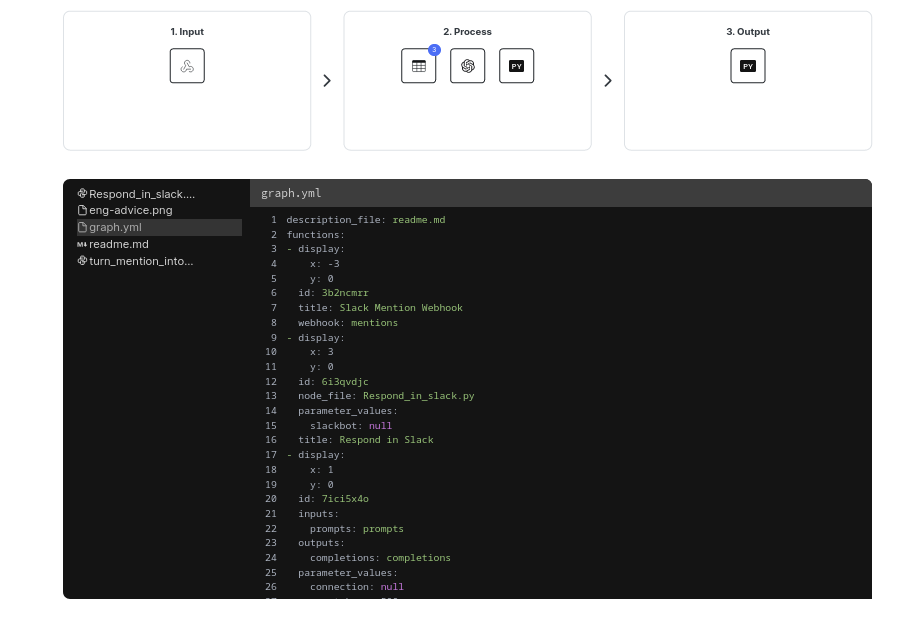
The app is defined in code and contains the methods you call as well as the graph object.
Deployment and runs are all handled by the hosted platform.
This seems to be the most full featured of the hosted options. It doesn’t have some of the components available in LangChain baked in, but you should be able to import them and use them in a workflow.
HumanLoop
humanloop website
Tagline: “Make GPT-3 faster, cheaper, more effective”
It’s hard to tell, what this is exactly because it’s behind a request early access form. From the website, it seems to be an app platform focused on a/b testing models, rapidly switching between them, and tag examples for fine tuning to drive cost effectiveness.
Yurts.ai
yurts.ai website
Tagline: “We build the blocks on the foundations. You build the rest.”
Early access, but no public availability. It seems focused on rapidly rolling out apps in a bunch of different domains. Perhaps they’re running a series of small bets or developing intuition for a LLM application framework and platform.
LLM model providers
There are several hosted and open source options for LLMs:
HuggingFace
Hugging Face has the largest open source model repository. Most recent LLM researchers publish their models to the repo along with their paper.
If you are planning to self host, this is a great place to get your foundation model. They also provide hosted solutions and infrastructure to train models.
OpenAI/azure
You can access hosted versions if the OpenAI models using either Azure OpenAI service or OpenAI.
If you want a hosted version of one of the GPT series models, this is your best choice.
Cohere
Cohere’s tagline is “Making NLP part of every developer’s toolkit”. They provide endpoints to classify, generate, and embed text. Their goal is it easy for developers to use NLP, and their sdk is very streamlined. For instance, fine-tuning is an easy to use endpoint with very little configuration.
For engineers that want an easy way to get into LLM models, cohere is a good choice.
AI21 Studio
AI21 studio is creating their own modified version of the GPT models known as the “Jurassic” series. They allow for a larger number of tokens in the context.
Worth keeping an eye on them if you’re using GPT-like models and want to see if performance or price are better for you use case.
Aleph Alpha
Aleph Alpha is an EU based LLM provider. FOr those that need something in the EU and with EU languages it’s a good choice.
Baseplate
Baseplate is a very new entrant (YC W23) to the space. They focus on fine tuning language models for increased domain specific performance and reduced cost.