Q&A with GPT-Index
As I mentioned in a previous post, I’m building out a simple app using LLMs (Large Language Models). In this post I’m going to go over how to use GPT Index to build a Q&A chatbot and compare performance with a few different LLMs.
GPT Index
GPT Index is a project consisting of a set of data structures designed to make it easier to use large external knowledge bases with LLMs.
GPT Index is a python project started by Jerry Liu, github, docs. Using GPT Index to build a Q&A chatbot can be very simple,
from gpt_index import GPTSimpleVectorIndex, SimpleDirectoryReader
from IPython.display import Markdown, display
documents = SimpleDirectoryReader('data').load_data()
index = GPTSimpleVectorIndex(documents)
That being said, you’re also able to customize it extensively. You can choose from a variety of embedding models and LLMs. There are multiple kinds of indexes you an choose for a variety of use cases.
How it works
My use case is searching for information across documents. I want to load data from a bunch of different sources and then query it. The way information flows through the app is roughly like this:
Preprocessing:
- download documents from the web.
- structure the data.
- compute the sentence embedding for the document text (get a vector).
- load the text and metadata into an index along with the embedding vector.
Question answering:
- a user enters a text query.
- the text query is used to compute an embedding vector (the same way the documents were).
- find
N >= 1documents in the index using vector similarity search. - fill out a prompt using the first document and the original user query. send to a LLM.
- for each additional document write a prompt with the “running response” and ask the LLM again.
GPT Index uses LangChain under the hood to take care of Preprocessing 3,4 and all of the step in Question answering.
The Code
from bs4 import BeautifulSoup
import re
from gpt_index import Document
from gpt_index import GPTSimpleVectorIndex
docs = []
## I downloaded the docs for these projects earlier and put them in my
## local file structure in the `sites` folder.
for doc_index in ['gpt-index-latest', 'langchain-latest']:
html = open(f'sites/{doc_index}/index.html','r').read()
# parsing the html file
soup = BeautifulSoup(html, 'html.parser')
def next_element(elem):
while elem is not None:
# Find next element, skip NavigableString objects
elem = elem.next_sibling
if hasattr(elem, 'name'):
return elem
# we're looking for all of the header elements
re_pattern = re.compile('^h[1-6]')
headers = soup.find_all(re_pattern)
document_sections = []
for header in headers:
section = 'Library: ' + doc_index + '\n'
section += 'Title: ' + str(header.text).strip('#') + '\n'
for link in BeautifulSoup(str(header), 'html.parser').find_all('a'):
section += 'HREF: ' + str(link.get('href'))
elem = next_element(header)
# for each header we collect all of the text of the section into a document
while elem is not None and elem not in headers:
if elem.text.strip() is not None:
section += '\n' + str(elem.text.strip('\n '))
elem = next_element(elem)
docs.append(section)
### pull the documents from the text sections from the html version of "read the docs"
documents = [Document(t) for t in docs]
### alternatively
### pull the data from pdfs printed from "read the docs"
### this did not perform as well.
# from gpt_index import SimpleDirectoryReader
# documents = SimpleDirectoryReader('pdfs').load_data()
index = GPTSimpleVectorIndex(documents)
index.save_to_disk('openai_index.json')
response = index.query("who wrote LangChain?", similarity_top_k=4)
print(response)
response = index.query("what vector stores can you use with LangChain?", similarity_top_k=4)
print(response)
response = index.query("what vector stores can you use with GPT Index?", similarity_top_k=4)
print(response)
Q&A results
The default provider for LLM and embeddings is OpenAI. The default embedding model is text-embedding-ada-002 and the default LLM is text-davinci-003. I inserted some logging into the library to see how GPT-3 answered the question and then refined it as more context was provided.
response = index.query(“what vector stores can you use with LangChain?”, similarity_top_k=4)
On the first loop the context provided is not very good. Despite instructions not to rely on previous knowledge, it must use some knowledge to determine some technologies.
Context information is below.
---------------------
Library: langchain-latest
Title: Vectorstores
HREF: #vectorstores
These are datastores that store embeddings of documents in vector form.
They expose a method for passing in a string and finding similar documents.
---------------------
Given the context information and not prior knowledge, answer the question: what vector stores can you use with LangChain?
==============================
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, and PostgreSQL.
This is a little disappointing. None of these databases are primarily used as vector stores. It’s not obvious to me where the information is coming from.
Here is the second turn at answering the question:
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, and PostgreSQL.
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: VectorStore
HREF: #vectorstore
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
For a more detailed walkthrough of the Pinecone wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, and PostgreSQL, as well as a wrapper around Pinecone indexes, allowing you to use it as a vectorstore, whether for semantic search or example selection. To import this vectorstore, use the following code: from langchain.vectorstores import Pinecone. For a more detailed walkthrough of the Pinecone wrapper, see this notebook.
So, here you can see that the context provided from the vector similarity search does add information and that information was included in the response. In the future, I would add in additional methods that would add in images and links to the docs that this context came from and/or is referencing.
Once again:
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, and PostgreSQL, as well as a wrapper around Pinecone indexes, allowing you to use it as a vectorstore, whether for semantic search or example selection. To import this vectorstore, use the following code: from langchain.vectorstores import Pinecone. For a more detailed walkthrough of the Pinecone wrapper, see this notebook.
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: VectorStore
HREF: #vectorstore
There exists a wrapper around Weaviate indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Weaviate
For a more detailed walkthrough of the Weaviate wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, PostgreSQL, and Weaviate, as well as a wrapper around Pinecone and Weaviate indexes, allowing you to use them as vectorstores, whether for semantic search or example selection. To import these vectorstores, use the following code: from langchain.vectorstores import Pinecone and from langchain.vectorstores import Weaviate. For a more detailed walkthrough of the Pinecone and Weaviate wrappers, see the respective notebooks.
This is a good turn. Weviate is mentioned in the context and is added to the reply.
Finally for turn 4 of 4 (similarity_top_k=4):
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, PostgreSQL, and Weaviate, as well as a wrapper around Pinecone and Weaviate indexes, allowing you to use them as vectorstores, whether for semantic search or example selection. To import these vectorstores, use the following code: from langchain.vectorstores import Pinecone and from langchain.vectorstores import Weaviate. For a more detailed walkthrough of the Pinecone and Weaviate wrappers, see the respective notebooks.
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: Wrappers
HREF: #wrappers
VectorStore#
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
For a more detailed walkthrough of the Pinecone wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
LangChain supports a variety of vector stores, including Elasticsearch, Redis, MongoDB, PostgreSQL, and Weaviate, as well as a wrapper around Pinecone and Weaviate indexes, allowing you to use them as vectorstores, whether for semantic search or example selection. To import these vectorstores, use the following code: from langchain.vectorstores import Pinecone and from langchain.vectorstores import Weaviate. For a more detailed walkthrough of the Pinecone and Weaviate wrappers, see the respective notebooks. Additionally, there exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore, whether for semantic search or example selection. To import this vectorstore, use the following code: from langchain.vectorstores import Pinecone. For a more detailed walkthrough of the Pinecone wrapper, see this notebook.
Now we’ve duplicated one of the vector stores. This is likely due to a repeated piece of information in the docs. I could get rid of this by being more careful in the parse to deduplicate the docs when adding them.
Embedding Analysis
The embedding part is easier than the text generation part. One easy way to tell that is from the defaults used in GPT Index. It uses an older cheaper embedding model, but uses the newest, slowest, most expensive LLM for text generation. For a cost and speed perspective, it would be even better if we could just do the embeddings locally. Because GPT Index uses a LangChain HuggingFace embeddings wrapper, you can use any of the models from sentence_transformers (or another module for the HuggingFace hub).
I chose to try the pretrained models available from SentenceTransformer. They are pretty easy to instantiate, are well documented, and up to date.
I tried these embedding models
sentence-transformers/all-mpnet-base-v1sentence-transformers/multi-qa-mpnet-base-dot-v1
Both of these performed equally as well over the queries I had. They are both fairly small, fast, and produce good embeddings. I like these two because one is better at Semantic search, the other is good at Sentence embeddings. Both take in 512 token inputs (good for longer sentences and sections) and make 768 dimensional embeddings.
The data from the hug tells the same story:
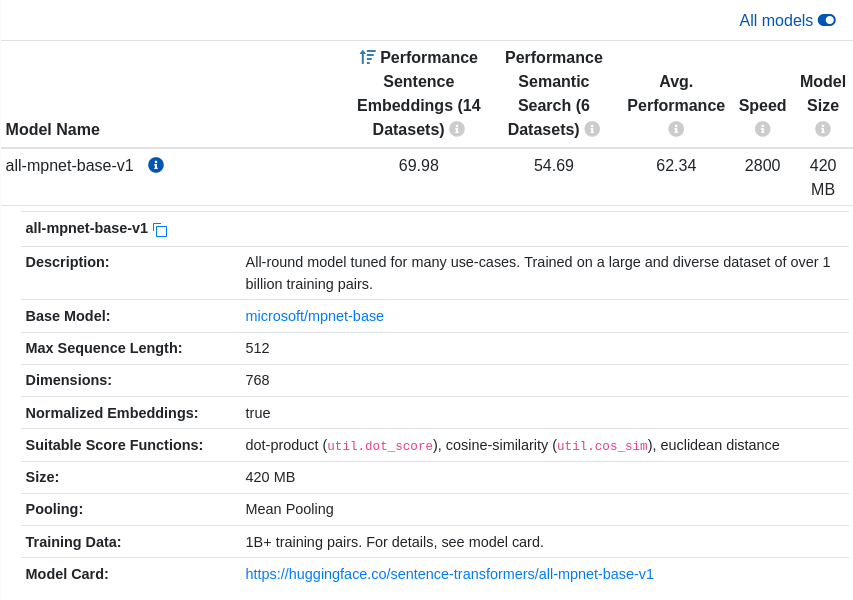
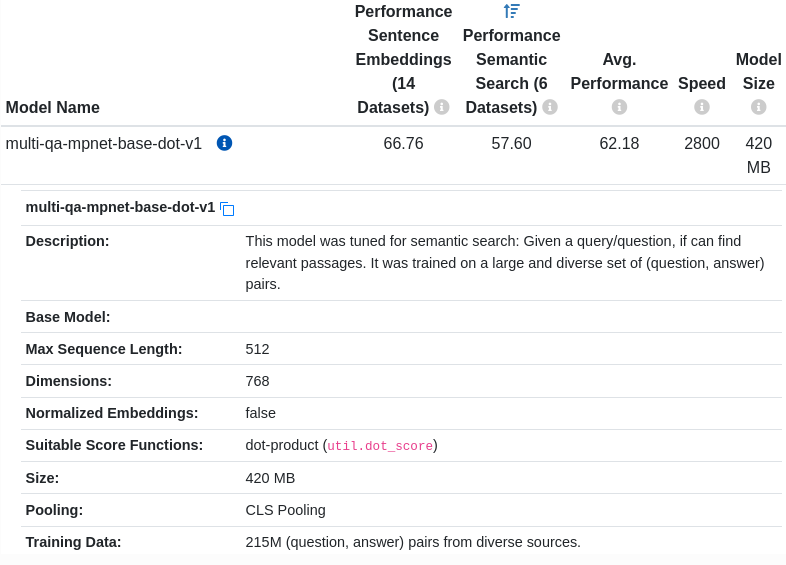
Using these models resulted in the same end results for my queries.
LLM Cost + Performance Analysis
I am cost sensitive. I want to compare the results across different embedding and LLM models and choose the best one. If two perform about the same, I’ll choose a cheaper one. That was the motivation behind the embedding analysis. I’ll do the same thing for the LLM part. Here I’ll compare some local versions: flan-t5-xl and gpt2-xl, to the paid versions from OpenAI, Cohere, and AI21Studio.
For this example I used the docs from lang-chain and from gpt-index which had around 1.1M tokens. I then made 8 different queries (4 of which are in the code above).
Local models
The local models are just terrible. The text they generate, when substantial enough to judge, is irrelevant at best. The flan-t5-xl model gives a result of:
a vector
The gpt2-xl model yields complete nonsense.
The EleutherAI/gpt-neo-2.7B yields:
The vectorstore is a wrapper around Pinecone indexes.
repeated until the token count runs out.
The default prompt must have been tuned to give good results using OpenAI. It looks like the ElutherAI model might be able to do something reasonable, but it would take significant prompt engineering.
OpenAI
OpenAI is the baseline. The completions are pretty good and the price isn;t too bad.
costs:
- ada - 600 embedding requests. 1132064 tokens. $0.37
- davinci - 8 response. 1.4k tokens. 126 completion tokens. $0.03
So, the cost per Q&A completion are around $0.0035.
Cohere
Switching over to the Cohere LLM is pretty easy.
from langchain import Cohere
# You can set these however you want default temp is 0.75 and k=0 (number of tokens considered at each point)
cohere = Cohere(temperature=3e-1, k=5)
llm_predictor = LLMPredictor(llm=cohere)
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, embed_model=embed_model)
However, the results are rather poor. They do tell a narrative, however that narrative doesn’t have anything to do with the question. I suspect this might be remedies by doing some experimentation with the prompt.
Here’s an example result chain:
Context information is below.
---------------------
Library: langchain-latest
Title: Vectorstores
HREF: #vectorstores
These are datastores that store embeddings of documents in vector form.
They expose a method for passing in a string and finding similar documents.
---------------------
Given the context information and not prior knowledge, answer the question: what vector stores can you use with LangChain?
==============================
---------------------
The answer is:
2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2
This first chain is a complete mystery to me.
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer: ---------------------
The answer is:
2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: VectorStore
HREF: #vectorstore
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
For a more detailed walkthrough of the Pinecone wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
One of the most common vectorstore use-cases is for example selection,
where the user is presented with a list of example sentences that are all
related to the same topic.
The original question is as follows: how do you use the LangChain's vectorstore?
We have provided an existing answer: -----------------------
The answer is:
2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2
The narrative is improved, but the answer is still nonsense.
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
One of the most common vectorstore use-cases is for example selection,
where the user is presented with a list of example sentences that are all
related to the same topic.
The original question is as follows: how do you use the LangChain's vectorstore?
We have provided an existing answer: -----------------------
The answer is:
2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2.2
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: Wrappers
HREF: #wrappers
VectorStore#
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
For a more detailed walkthrough of the Pinecone wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
---
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
The vectorstore is initialized with a Pinecone index, and can be used in the same way as any other vectorstore.
In this example, we will show you how to use the vectorstore to search for example sentences related to the topic "food".
To use the vectorstore, you will need to import it.
In this example we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Pinecone index, and can be used in the same way as any other vectorstore.
In this example we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Pinecone index, and can be used in the same way as any other vectorstore.
In this example, we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Pinecone index, and can
Now we have some pinecone info in the answer.
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
---
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
The vectorstore is initialized with a Pinecone index, and can be used in the same way as any other vectorstore.
In this example, we will show you how to use the vectorstore to search for example sentences related to the topic "food".
To use the vectorstore, you will need to import it.
In this example we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Pinecone index, and can be used in the same way as any other vectorstore.
In this example we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Pinecone index, and can be used in the same way as any other vectorstore.
In this example, we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Pinecone index, and can
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: VectorStore
HREF: #vectorstore
There exists a wrapper around Weaviate indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Weaviate
For a more detailed walkthrough of the Weaviate wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
The vectorstore is initialized with a Weaviate index, and can be used in the same way as any other vectorstore.
In this example, we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Weaviate index, and can be used in the same way as any other vectorstore.
In this example, we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Weaviate index, and can be used in the same way as any other vectorstore.
In this example, we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Weaviate index, and can be used in the same way as any other vectorstore.
In this example, we will be using the English Wikipedia dump, which is available here.
In this example, we will be using the English Wikipedia dump, which is available here.
The vectorstore is initialized with a Weaviate index, and can be used in the same way as any other vectorstore.
------------
Given the new context, refine
Now the pinecone info is gone and we have weaviate info instead.
The Cohere model does not seem to be able to take the last answer and merge new information into it like the OpenAI model does.
From the pricing perspective Cohere is cheaper than OpenAI for our use case. Instead of billing by token, they bill by request. If we were going ot use the cohere embeddings, then we’d be paying more. Since we’re just calling generate, out cost is about 50% of OpenAI.
- $1/1000 - embed: $0.60 (we had 600 calls to the embedding method)
- $2/1000 - gen: $0.016 (8 calls)
Regardless of the cost, I couldn’t use the LLM as is. If I had a use case where I knew I would be making a lot of queries, I would definitely spend some time doing prompt engineering to make Cohere perform better.
AI21
AI21 is also easy to instantiate:
from langchain import AI21
ai21 = AI21()
llm_predictor = LLMPredictor(llm=ai21)
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, embed_model=embed_model)
If you’re on langchain==0.77 there’s a bug where you’ll need to edit an __init__.py file ot include this in the import even though the code is there.
Similar to Cohere, AI21 does not do well with the default prompts.
Context information is below.
---------------------
Library: langchain-latest
Title: Vectorstores
HREF: #vectorstores
These are datastores that store embeddings of documents in vector form.
They expose a method for passing in a string and finding similar documents.
---------------------
Given the context information and not prior knowledge, answer the question: what vector stores can you use with LangChain?
==============================
---------------------
Context information
A:
VectorStores
1. [Word2Vec](https://code.google.com/archive/p/word2vec/)
2. [GloVe](http://nlp.stanford.edu/projects/glove/)
3. [FastText](http://fasttext.cc/)
4. [SkipGram](https://code.google.com/archive/p/skip-gram/)
5. [GoogleNews](http://code.google.com/archive/p/word2vec/)
6. [GoogleNews](http://code.google.com/archive/p/word2vec/)
7. [GoogleNews](http://code.google.com/archive/p/word2vec/)
8. [GoogleNews](http://code.google.com/archive/p/word2vec/)
It looks like AI21 is trying to pull something relevant out of it’s memory, but can’t quite do it.
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
---------------------
Context information
A:
VectorStores
1. [Word2Vec](https://code.google.com/archive/p/word2vec/)
2. [GloVe](http://nlp.stanford.edu/projects/glove/)
3. [FastText](http://fasttext.cc/)
4. [SkipGram](https://code.google.com/archive/p/skip-gram/)
5. [GoogleNews](http://code.google.com/archive/p/word2vec/)
6. [GoogleNews](http://code.google.com/archive/p/word2vec/)
7. [GoogleNews](http://code.google.com/archive/p/word2vec/)
8. [GoogleNews](http://code.google.com/archive/p/word2vec/)
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: VectorStore
HREF: #vectorstore
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
For a more detailed walkthrough of the Pinecone wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
Looks like it’s completely given up now.
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: Wrappers
HREF: #wrappers
VectorStore#
There exists a wrapper around Pinecone indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Pinecone
For a more detailed walkthrough of the Pinecone wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
nothing.
The original question is as follows: what vector stores can you use with LangChain?
We have provided an existing answer:
We have the opportunity to refine the existing answer(only if needed) with some more context below.
------------
Library: langchain-latest
Title: VectorStore
HREF: #vectorstore
There exists a wrapper around Weaviate indexes, allowing you to use it as a vectorstore,
whether for semantic search or example selection.
To import this vectorstore:
from langchain.vectorstores import Weaviate
For a more detailed walkthrough of the Weaviate wrapper, see this notebook
------------
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
==============================
Although there is information in this query about a vector store, none of it makes it to the response.
From the pricing perspective, they have yet another pricing model. AI21 prices based on the number of tokens generated by the model. Input is free.
Pricing for this use case seems to be about the same as OpenAI. For our queries we generated
- $0.25/1K tokens: $0.03
Again, the results are underwhelming likely because the prompts have been tuned to perform well on the OpenAI LLMs and not the AI21 ones.
Choice of Vector Store
The only other vector store that appears to be relevant for my use case is the GPTFaissIndex. To use this one you have to install or build the faiss package.
# 768 is the dim for HuggingFaceEmbeddings - sentence-transformers/all-mpnet-base-v2
import faiss
from gpt_index import GPTFaissIndex
faiss_index = faiss.IndexFlatL2(768)
index = GPTFaissIndex(documents, faiss_index=faiss_index, embed_model=embed_model)
However, I did not get different results using this vector store for my queries. It appears to be a good choice if you have a very large number of vectors. Building it on a new GPU without using anaconda was kind of a pain in the ass.
Conclusion
It’s pretty easy to get started with GPT Index and build something reasonable. You can use local embeddings and do pretty well. However, the only LLM that really worked well with out of the box prompts was the OpenAI one. That’s not surprising because I think the author pretty much only tests with OpenAI. With some additional work I am guessing the other LLMs could be OK (not very certain though).